東京, 04月04日 /AJMEDIA/
最近の人工知能(AI)業界では音声生成AIモデルが広く注目を集めており、OpenAIも自社の新たな音声生成モデル「Voice Engine」を発表している。Stable AIもその流れに乗り、最新の音声生成モデルを公開した。
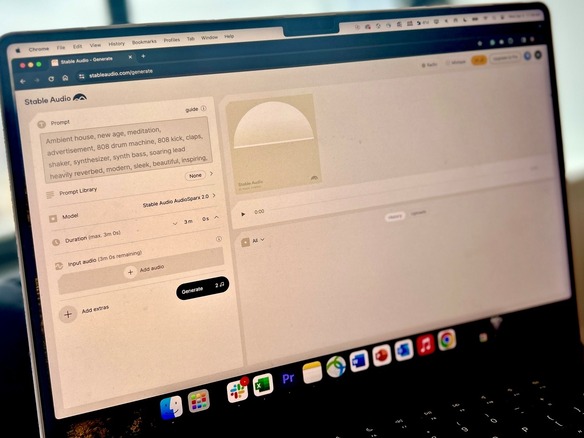
画像生成AIモデル「Stable Diffusion」で一躍有名になったオープンソースAI企業であるStability AIは米国時間4月3日、「Stable Audio 2.0」を発表した。この新モデルは、同社の前モデルである「Stable Audio 1.0」を大幅にアップグレードしたもので、テキスト以外の情報から曲やサウンドを生成する機能も追加されている。
Stable Audio 2.0は、音声から音声を生成する機能を持っており、ユーザーは音声のサンプルをアップロードして、自然言語のプロンプトを使ってさまざまな曲やサウンドを作成できる。またスタイル転換機能を使えば、生成された音声やアップロードされた音声を、特定のスタイルやトーンに修正することもできる。
創作物の完全性やアーティストの権利を保護するため、Stable Audio 2.0にアップロードされる情報には著作権を侵害する内容が含まれていてはならない。同社は、著作権侵害を未然に防ぎ、ユーザーがルールを順守していることを確認するため、Audible Magicが提供するコンテンツ認識技術を使用している。
Stable Audio 1.0と2.0は、「AudioSparx」の80万件以上のデータでトレーニングされている。AudioSparxを利用するアーティストは、Stable Audioのトレーニングでの使用をオプトアウトする選択肢が与えられているという。
また新しいモデルでは、44.1kHzステレオ音声で3分までの長さの曲を作成できるようになった。前回のモデルでは45秒までの曲しか作成できなかったことを考えれば、大幅な機能向上だ。生成される音声は、メロディー、伴奏、効果音などさまざまだ。
このモデルはすでにStable Audioのウェブサイトで無償で公開されている。サイトにアクセスしてStable AIのアカウントかGoogleアカウントでログインすれば、簡単に試すことができる。